Why Traditional RAG Fails and How Structured Data RAG Solves It
Table of Contents Introduction If you’ve been keeping up with the world of AI tools and technologies, you’ve probably come
Table of Contents Introduction If you’ve been keeping up with the world of AI tools and technologies, you’ve probably come
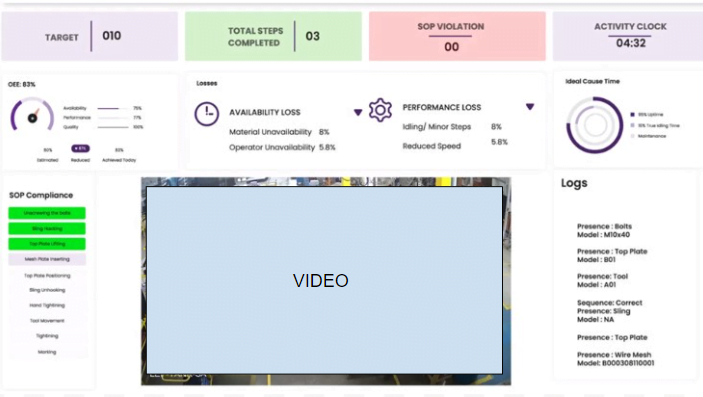
Providing real-time alerts and analytics for workplace safety and compliance Safety Insights – A Solution for Workplace Compliance and Safety

USA

Saudi Arabia

UAE (Dubai)

Singapore

UK

South Africa